
Deep Learning
Bayesian modeling and variational learning
In Bayesian data analysis and estimation methods, all the uncertain quantities are modeled in terms of their joint probability distribution. The key principle is to construct the joint posterior distribution for all the unknown quantities in a model, given the data sample. This posterior distribution contains all the relevant information on the parameters to be estimated in parametric models, or the predictions in non-parametric prediction or classification tasks (MacKay, 2003; Bishop, 2006).
The simplest "Bayesian" method, maximum a posteriori (MAP) method, finds the parameter values that maximize the posterior probability density. However, with such point estimates model order estimation and overfitting (choosing too complicated a model for the given data) can be severe problems.
In fully Bayesian methods, the entire posterior distribution is used for finding estimates and predictions which are sensitive to regions where the probability mass is large instead of being sensitive to high values of the probability density. Furthermore, the probabilities of each model can be evaluated and compared, and the most probable model selected. This procedure largely solves the problems related to the model complexity and choice of a specific model among several candidates (MacKay, 2003; Bishop, 2006; Lappalainen and Miskin, 2000).
A problem with fully Bayesian estimation is that the posterior distribution has a highly complicated form except for in the simplest problems. Therefore it is too difficult to handle exactly, and some approximative method must be used. In Markov Chain Monte Carlo (MCMC) methods (MacKay, 2003; Bishop, 2006), samples are generated from the posterior distribution to compute the desired estimates. However, MCMC methods are often computationally too demanding in the unsupervised learning problems which we have studied, because the number of unknown parameters or values to be estimated can be quite high.
We have studied and applied variational Bayesian (VB) methods (formerly called also Bayesian ensemble learning methods) to various unsupervised learning problems. In VB methods, the exact posterior distribution is approximated with a simpler distribution. This approximating distribution is then fitted to the posterior distribution using Kullback-Leibler divergence, which measures the difference between two distributions (MacKay, 2003; Lappalainen and Miskin, 2000).
The approximating distribution is often taken a diagonal multivariate Gaussian distribution, because the computations become then tractable. Even this crude approximation is adequate for finding the region where the mass of the actual posterior density is concentrated. The mean values of the Gaussian approximation provide reasonably good point estimates of the unknown parameters, and the respective variances measure the reliability of these estimates.
Variational Bayesian learning is closely related to information theoretic approaches which minimize the description length of the data. In the probabilistic framework, we try to find the sources or factors and the mapping which most probably correspond to the observed data. In the information theoretic framework, this corresponds to finding the sources and the mapping that can generate the observed data and have the minimum total complexity. The information theoretic view also provides insights to many aspects of learning and helps explain several common problems; see (Honkela and Valpola, 2004).
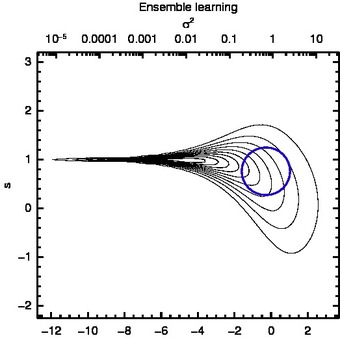
Explanation of the figure
The figure shows an example of a posterior probability density function (pdf) which has a very narrow but high peak. Maximum a posteriori (MAP) method provides an estimate which lies at the tip of this peak. However, the probability mass there is very low. On the contrary, variational Bayesian learning (ensemble learning) provides an estimate which is sensitive to the area of largest mass of the posterior pdf. This is marked by the blue circle in the figure.
References
C.M. Bishop, Pattern Recognition and Machine Learning, Springer 2006. Home page of the book.
A. Honkela and H. Valpola, "Variational learning and bits-back coding: an information-theoretic view to Bayesian learning". IEEE Transactions on Neural Networks 15(4), 2004, pp. 800-810. Pdf (308k)
H. Lappalainen and J. Miskin, "Ensemble learning". In M. Girolami (Ed.) Advances in Independent Component Analysis, pp. 75-92, Springer-Verlag, 2000. Gzipped postscript (127k)
D.J.C. MacKay, Information Theory, Inference, and Learning Algorithms. Cambridge University Press, 2003. A home page of the book.