
Data mining group
Software
Absorbing random walk centrality
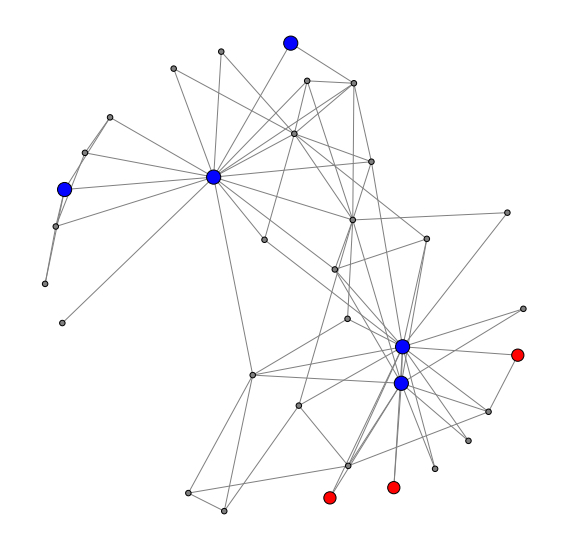
|
We study a new notion of graph centrality based on absorbing random walks. Given a graph G and a set of query nodes Q we consider central nodes to be absorbing for random walks that start at the query nodes Q. The goal is to find the set of k central nodes that minimizes the expected length of a random walk until absorption. Our method is presented in the following paper: Charalampos Mavroforakis, Michael Mathioudakis, Aristides Gionis, "Absorbing random-walk centrality: Theory and algorithms", International Conference on Data Mining (ICDM) 2015 (arxiv) The code and datasets are available in github. |
|---|
Metric learning and clustering with relative distance constraints

|
We consider the problem of metric learning and semi-supervised clustering when a set of relative distance constraints is provided as input, together with the observations. The relative distance constraints are elicited from questions of the form: "which one of the items i, j, and k is the least similar to the other two?" Our method is presented in the following paper: Ehsan Amid, Aristides Gionis, Antti Ukkonen, "A kernel-learning approach to semi-supervised clustering with relative distance comparisons", European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) 2015 (pdf) The code of the developed method can be found in github. |
|---|
Location estimation under uncertainty
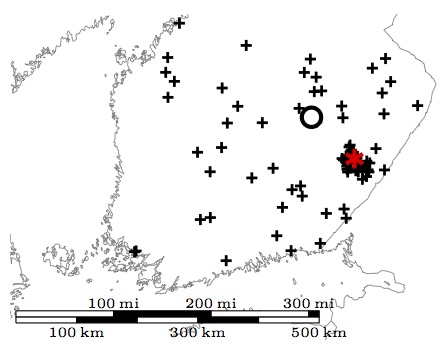
|
We consider the problem of inferring the geographical locations of linked objects, and we propose a probabilistic method that takes into account partial knowledge of object location, as well as the structure of the network that links the objects. Our method is presented in the following paper: Eric Malmi, Arno Solin, Aristides Gionis, "The blind leading the blind: Network-based location estimation under uncertainty", European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) 2015 (pdf) The code of the developed method can be found in github. |
|---|
Discovering social circles in twitter

|
We consider the task of organizing the twitter friends of a user into social circles, or lists. Rather than making every user start from scratch when organizing their friends, we want to find a way to use the lists already created by other users to recommend groupings automatically. Our method is presented in the following paper: Karmen Dykstra, Jefrey Lijffijt, Aristides Gionis, "Covering the egonet: A crowdsourcing approach to social circle discovery on twitter", to appear in the International Conference on Web and Social Media (ICWSM) 2015 (pdf) You can also check the relevant blog post. The code and the datasets used in the paper can be found in github. |
|---|
Comparing directed acyclic graphs
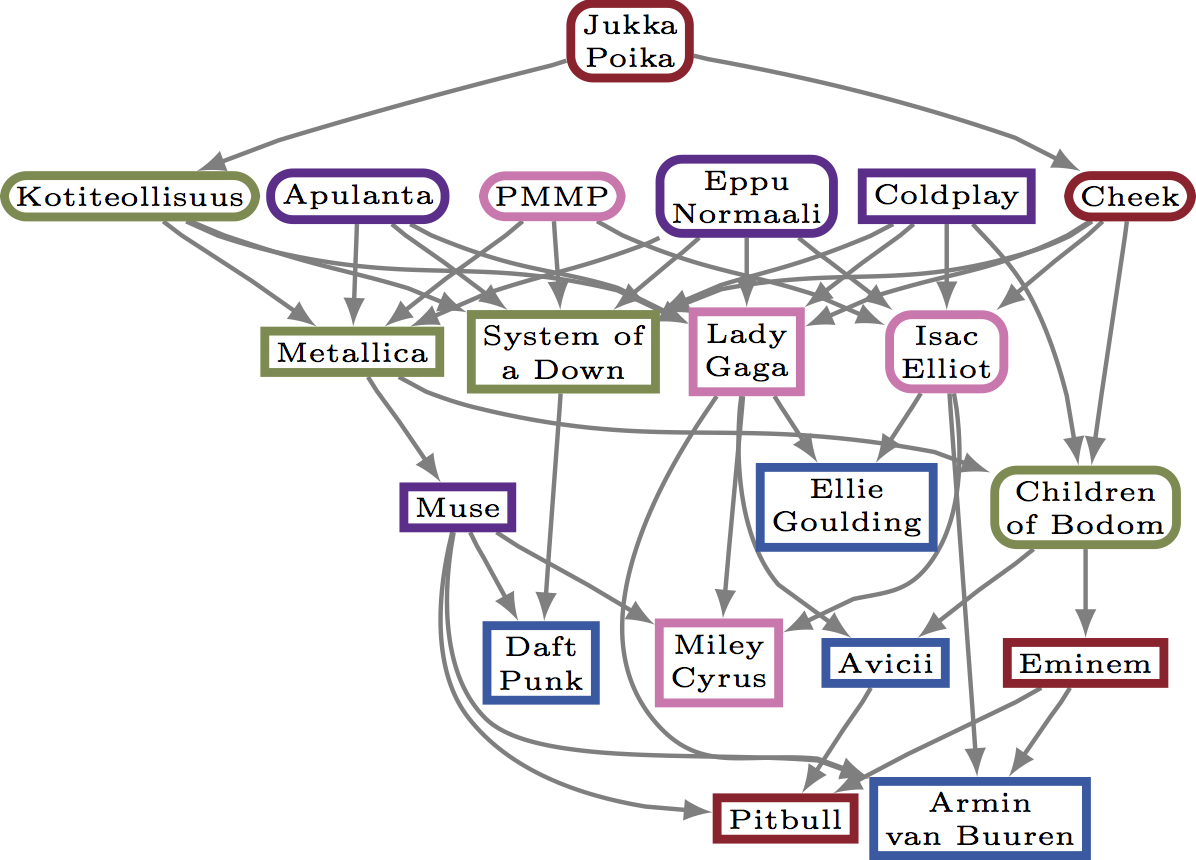
|
We study the problem of defining and computing distance measures between directed acycling graphs (dags). Our methods have applications in analyzing preference data and network information cascades. The work is presented in the following DMKD article. Eric Malmi, Nikolaj Tatti, Aristides Gionis, "Beyond rankings: comparing directed acyclic graphs", Data Mining and Knowledge Discovery (DMKD) 2015 (pdf of authors' copy; the final publication is available at link.springer.com) Here is also a relevant blog post. The code and the datasets used in the paper can be found in github. |
|---|
Longest common sub-patterns
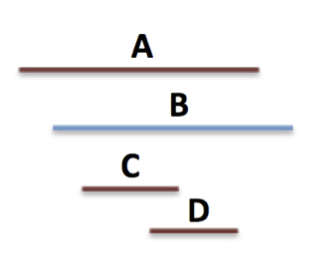
|
The LCSP problem asks to find large common patterns in temporal event sequences. An exact algorithm and polynomial-time heuristics are presented in our paper. Orestis Kostakis and Panagiotis Papapetrou, "Finding the longest common sub-pattern in sequences of temporal intervals", Journal of Data Mining and Knowledge Discovery (DMKD) 2015 (pdf) The datasets used in the paper and the code for the exact algorithm are available here. |
|---|
Bump hunting in the dark
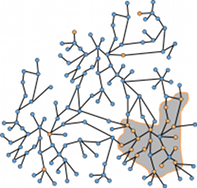
|
Starting from a set of query nodes of a graph, we want to find a subgraph with high discrepancy, meaning that the subgraph should have as many query nodes as possible, compared to non-query nodes. Furthermore, we assume that we do not know the graph structure in advance, and we want to discover it during the process. Our method is described in the following paper. Aristides Gionis, Michael Mathioudakis, Antti Ukkonen, "Bump hunting in the dark: Local discrepancy maximization on graphs", IEEE International Conference on Data Engineering (ICDE) 2015 (pdf) The datasets used in the paper and the code are available in bitbucket. |
|---|
Communities in interaction networks
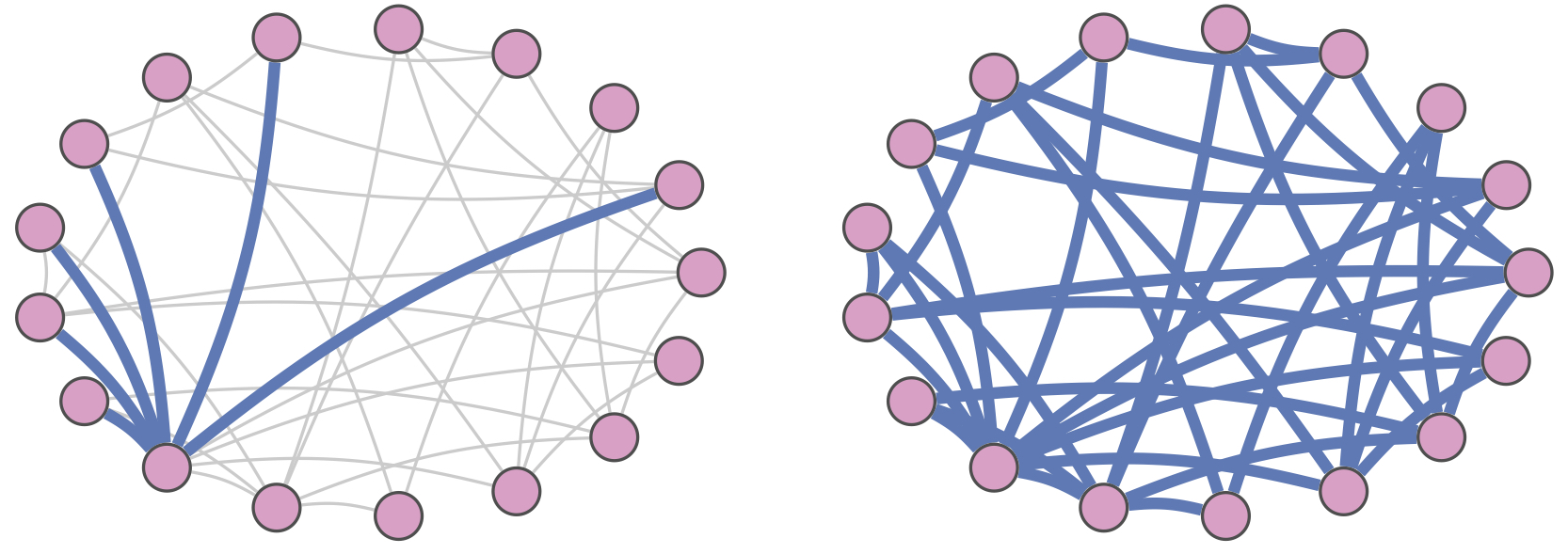
|
Given a graph with timestampts on the edges, we want to find a subgraph with many edges that take place in short time intervals. Our solution appears in the following paper. Polina Rozenshtein, Nikolaj Tatti, Aristides Gionis, "Discovering dynamic communities in interaction networks", European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) 2014 (pdf) The code is available in github. |
|---|
Event detection in graphs
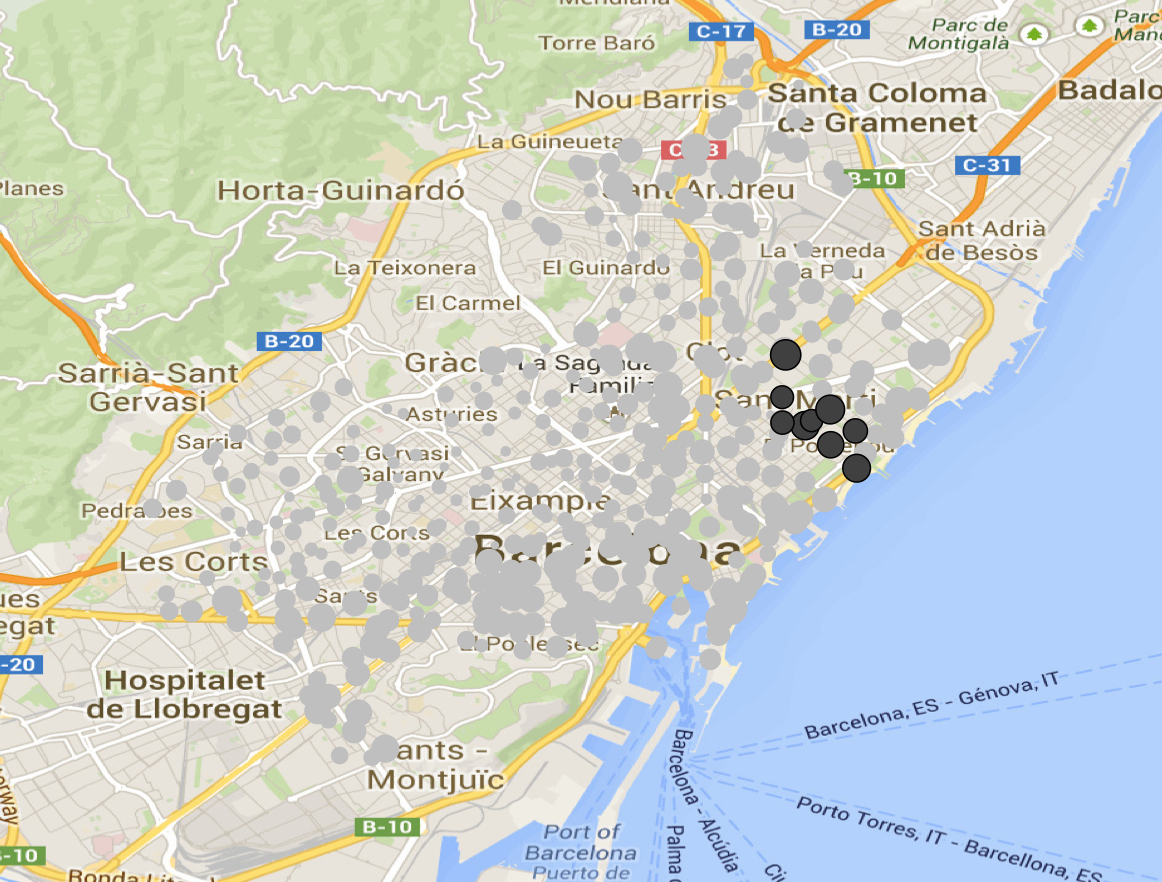
|
Given a graph with vertex weights and edge distances, we want to find a heavy subgraph whose vertices are near to each other. Our solution appears in the following paper. Polina Rozenshtein, Aris Anagnostopoulos, Aristides Gionis, Nikolaj Tatti, "Event detection in activity networks", ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2014 (pdf) The code is available in github. |
|---|
Agony
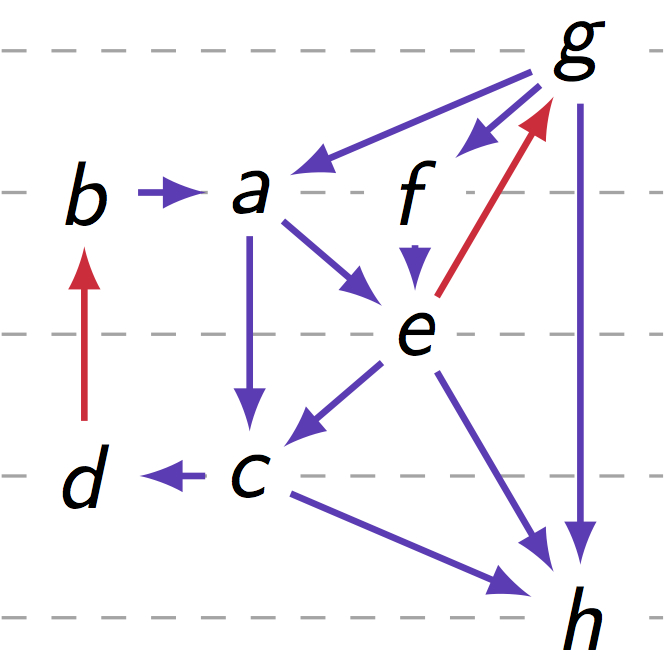
|
"Agony minimization" is a process that allows to rank the vertices of a directed graph in order to minimize certain cost on backward edges. The paper below introduces a method that runs in O(m^2) time, in worst-case, and it is faster in practice. The previous best method has running time O(nm^2). Nikolaj Tatti, "Faster way to agony: Discovering hierarchies in directed graphs", European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) 2014 (pdf) The code. |
|---|
Overlapping community detection in labeled graphs
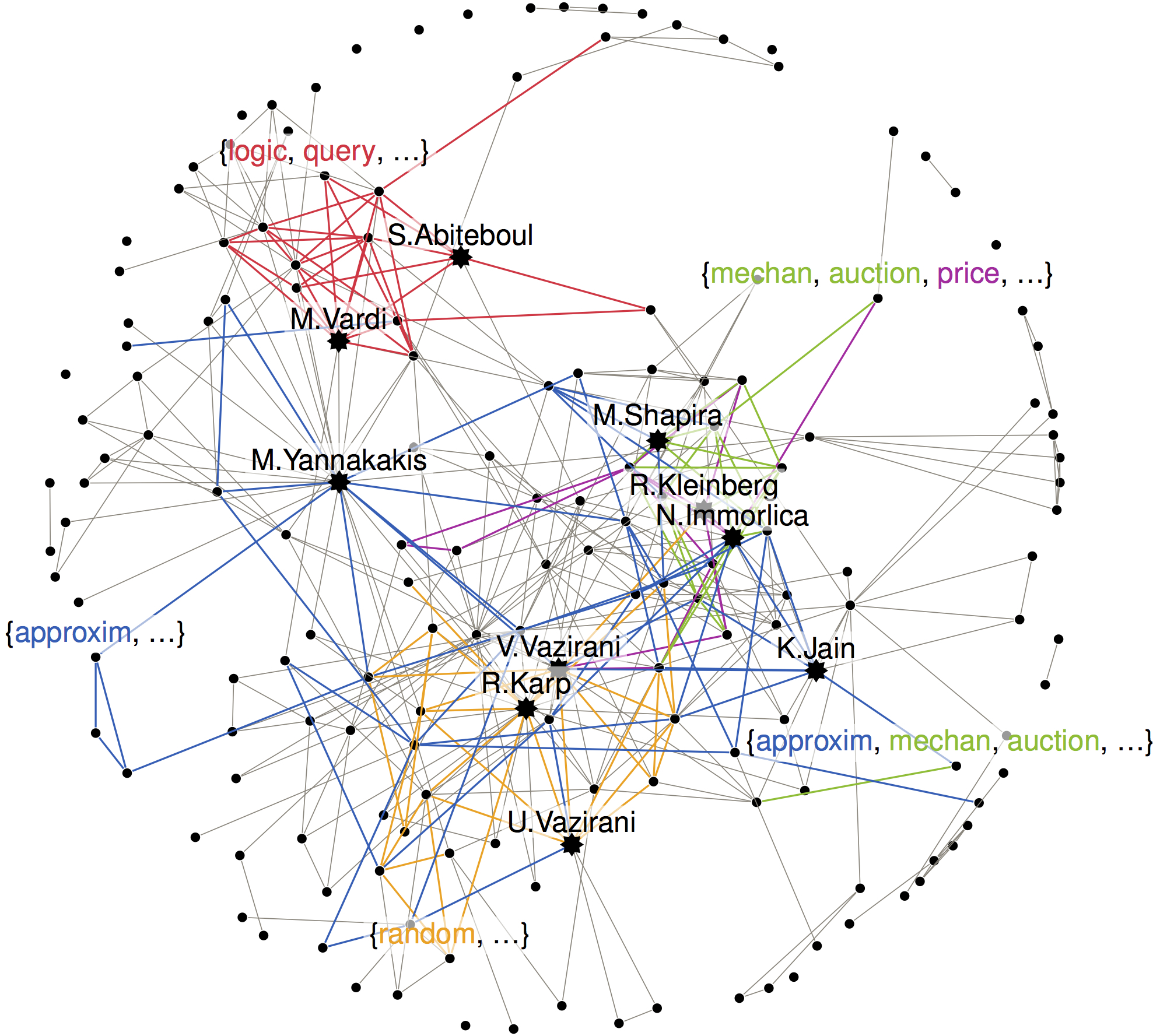
|
Given a graph with vertex labels, we ask to find top-k overlapping communities. We require that each community is described succinctly by few vertex labels and it induces a dense subgraph, while the top-k communities should cover as many edges of the graph as possible. Our solution is described in the following article. Esther Galbrun, Aristides Gionis, Nikolaj Tatti, "Overlapping community detection in labeled graphs", Data Mining and Knowledge Discovery (DMKD) 2014 (preprint) The code is available here. |
|---|
Confidence bands
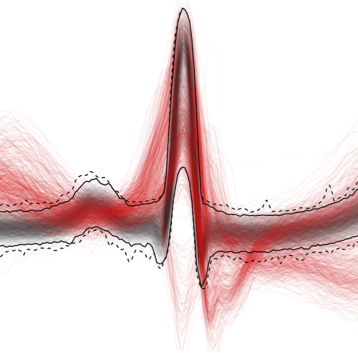
|
Confidence bands are used to visualize time-series data and provide an intuitive description of the data variability. We have developed a method to construct confidence bands such that the family-wise error rate is kept under control. The method is described in the following DMKD article. Jussi Korpela, Kai Puolamaki, Aristides Gionis "Confidence bands for time series data", Data Mining and Knowledge Discovery (DMKD) 2014 (pdf) The code and the scripts to reproduce the experiments in the paper are available here. |
|---|
SPIN: network response prediction
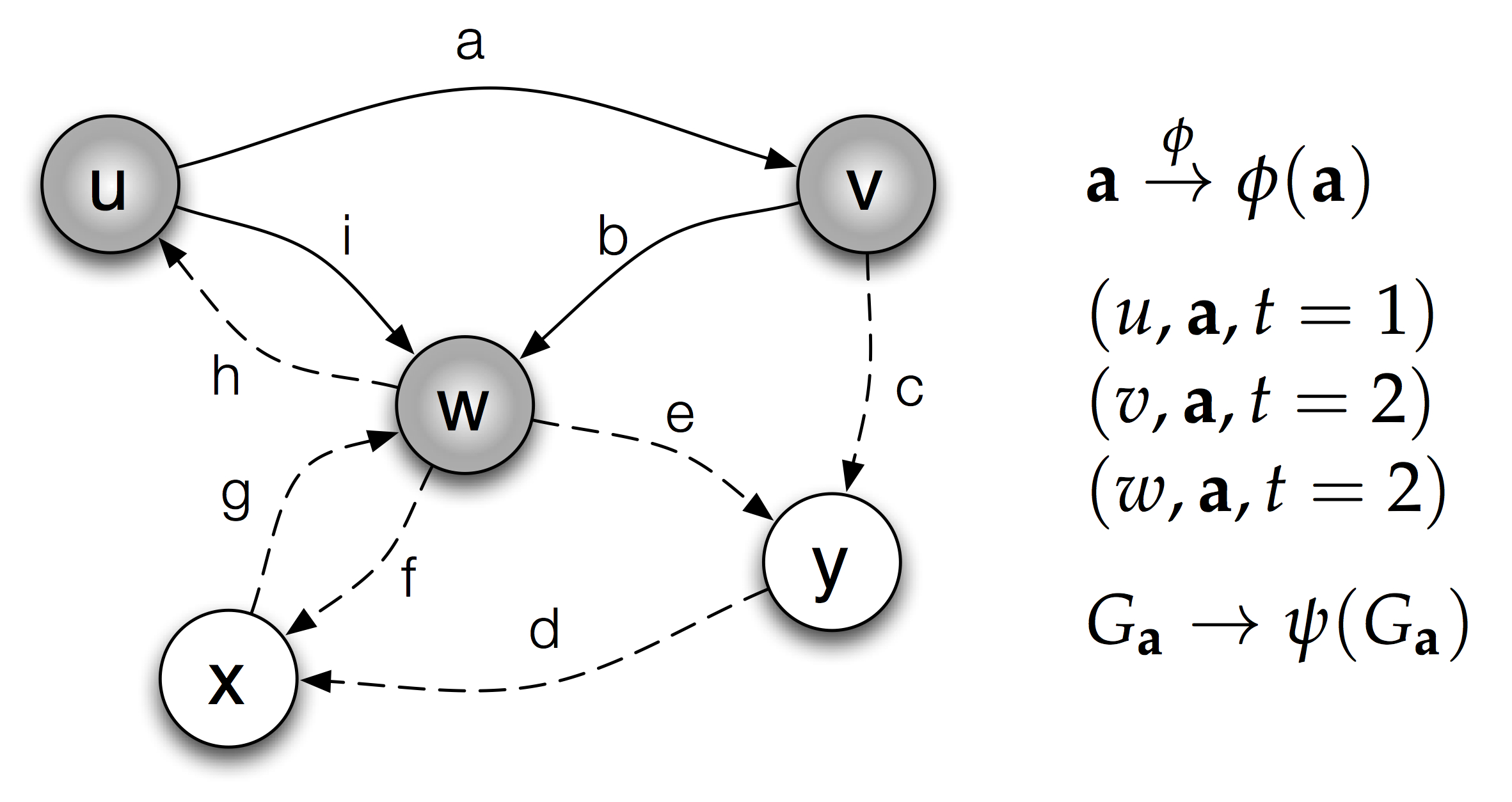
|
Given a collection of actions performed by users in a social network, predict which users will perform a given new action. The method is described in the following paper. A blogpost overview of the paper is also available. Hongyu Su, Aristides Gionis, Juho Rousu, "Structured prediction of network response", International Conference on Machine Learning (ICML) 2014 (pdf) The code and data are available in github. |
|---|
Nested communities

|
Given a set of nodes in a graph, we find a nested sequence of communities centered around those nodes. The density of the nested communities decreases as we move from the starting set of nodes to the periphery. The method is described in the following paper. Nikolaj Tatti and Aristides Gionis, "Discovering nested communities", European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) 2013 (pdf) The code is available here. |
|---|
Clustering aggregation
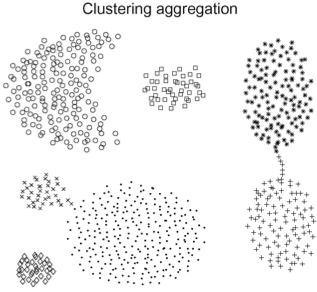
|
Given a set of clusterings, we want to find a single clustering that agrees as much as possible with the input clusterings. Here is the original implementation of our methods developed in an old paper. Aristides Gionis, Heikki Mannila, Panayiotis Tsaparas, "Clustering aggregation", ACM Transaction on Knowledge Discovery from Data (TKDD) 2007 |
|---|
 All software in this page is licensed under a Creative Commons Attribution 3.0 Unported License.
Whenever using our software please cite the corresponding publication.
The software may contain bugs; you should use it at your own risk.
All software in this page is licensed under a Creative Commons Attribution 3.0 Unported License.
Whenever using our software please cite the corresponding publication.
The software may contain bugs; you should use it at your own risk.