
Applications of Machine Learning Group
Research
Environmental modeling, Time series prediction, Process informatics, as well as Internet security and malfare detection are the main research areas of the AML (earlier EIML) research group.
Environmental Modeling
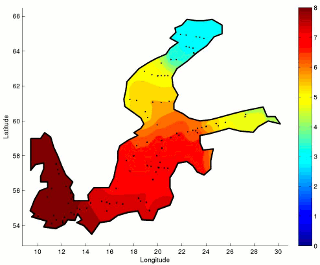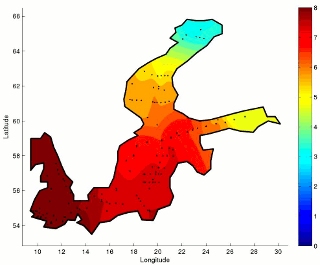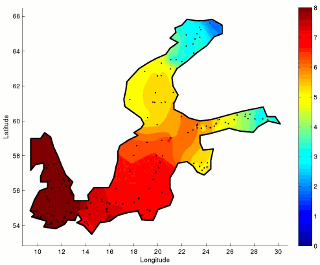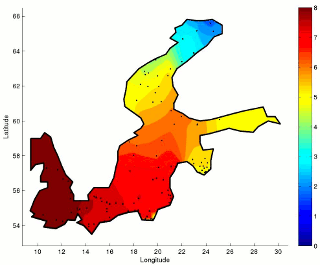
Environmental Sciences have seen a great deal of development and attention over the last few decades, fostered by an impressive improvement in observational capabilities and measurement procedures. The fields of environmental modeling and analysis seek to better understand phenomena ranging from Earth-Sun interactions to ecological changes caused by climatic factors. Traditional environmental modeling and analysis approaches emphasize deterministic models and standard statistical analyses, respectively. However, the application of further developed data-driven analysis methods has shown the great value of computational analysis in environmental monitoring research. Furthermore, these analyses have provided evidence for the feasibility of predicting environmental changes. Thus, linear and nonlinear methods and tools for the analysis and predictive modeling of environmental phenomena are sought.
In interpreting biological monitoring data, there is an even stronger need to develop new modeling techniques, because biota does not respond in a linear manner to environmental changes. In addition, a time lag between a stimulus and a response is common, e.g., a change in nutrient concentration and subsequent changes in algal growth, or turbidity of water. Hence, there is a demand for predictive and causal models.
In this context, we follow a multidisciplinary approach, involving diverse areas of machine learning. These include time series prediction, ensemble modeling, feature selection and dimension reduction. Our activity concentrates specially on developing new methods and tools motivated by real-world needs in close cooperation with experts in the field. Our current research spans a number of areas, including long-term prediction, spatial-temporal analysis, missing data, irregular and incomplete sampling, and time-frequency analysis. Among a number of application areas, we focus on Marine Biology.
Applications of our research have a direct relevance for the Baltic Sea countries. Sophisticated environmental models are needed and directly or indirectly requested by policy makers, industry and citizens. This is of special relevance in the context of regulations such as the EU Water Framework Directive, among others. Our research aims to contribute to the scientific and technological challenges posed by such regulations as well as general challenges in Environmental Sciences worldwide.
Time Series Prediction
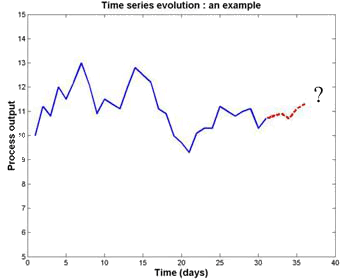
Time series forecasting is a challenge in many fields. In finance, one forecasts stock exchange or stock market indices; data processing specialists forecast the flow of information on their networks; producers of electricity forecast the electric load and hydrologists forecast river floods. The common point to their problems is the following: how can one analyze and use the past to predict the future? In general, these methods try to build a model of the process. The model is then used on the last values of the series to predict future values.
A new challenge in time series prediction is the long-term prediction also known as multiple step-ahead prediction. Many methods designed for time series forecasting perform well (depending on the complexity of the problem) on a rather short-term horizon but are rather poor on a longer-term one. This is due to the fact that these methods are usually designed to optimize the performance at short term, their use at longer term being not optimized. Furthermore, they generally carry out the prediction of a single value while the real problem sometimes requires predicting a vector of future values in one step.
One particular problem of long-term prediction is studied: the prediction of the electric load. This problem is very complex and is more and more crucial because of the liberalization of the electricity market. Electricity producers and network companies are looking for models to predict not only their needs for the next hours but also for next days and next weeks.
Process Informatics
Process Informatics investigates the development and application of modeling methods from adaptive informatics on measurements from process industry. The methods aim at representing complex chemical and physical processes with models directly derived from the data collected by the automation systems present in the process plants, without an explicit regard to the first principles.
We concentrate on algorithmic methods satistying properties like accuracy, robustness, computational efficiency and understandability. Accuracy, robustness and efficiency favor on-line implementations of the models in full-scale applications, whereas understandability permits the interpretation of the models from the aprioristic knowledge of the underlying phenomena. Such an approach to process modeling provides tools that can be used in real-time analysis and supervision of the processes and can be embedded in advanced model -based control strategies and optimization.
Specific application domains are chemometrics, spectroscopy, chromatography and on-line analytical technologies in process and power industry. On the algorithmic side we concentrate on methods for nonlinear dimensionality reduction, variable selection, functional and regularized regression.
Internet Security and Malware Detection
We have developed new techniques for identifying and classifying malware files, as well as improve website classification for internet security in the context of Tekes (The Finnish Funding Agency for Innovation) SHOK projects, and in close collaboration with the F-Secure Corporation.
The goal of anomaly and malware detection is to identify abnormal behavior and be able to signal the anomaly and take appropriate measures. The idea is here to deviate from the usual heuristics based methodology (commonly used in anti-virus software) to have a system capable of learning the main constituents of normal and abnormal behavior, and hence being able to differentiate and identify such files. This problem of abnormal/normal behavior identification becomes a problem of classification and clustering of samples between clean and malware, in non-Euclidean spaces and with large amounts of data. In addition, we deal with very specific requirements such as the need for absolutely zero false positive classifications, as well as highest possible coverage and close to real-time processing.
In website classification for internet security, one of the main goals is to improve existing website categorization tools by using solely the visual content from the website. This problem makes use of region of interest detection in images for the extraction of images features, as well as managing the important label noise in the classification problem. More specifically, while a website as a whole is of a certain class, all the images it holds do not have to belong to that same class, and therefore they act as noise in the labeling of the data. We have obtained good results, and our paper "Arbitrary Category Classification of Websites Based on Image Content" presenting them was published in the IEEE Computational Intelligence Magazine (May 2015) which has wide circulation.
In July 2014, we started the CloSe (Cloud Security Services) project funded by the Academy of Finland and Tekes in collaboration with several academic and industrial partners. In our subproject with the F-Secure Corp., the goal is to classify software made for Android mobile phone systems into bening and malicious ones. A practical problem in this application is that the data vectors have millions of components, which prevents the use of most standard classification methods. We have obtained reasonably good results by using the naive Bayes classifier, and recently improved them by using another classifier such as support vector machine or logistic regression on top of the naive Bayes classifier.